
아래 글은 Research Methods in Human-Computer Interaction(2nd Edition)을 읽고 정리한 글입니다.
HCI(인간-컴퓨터 상호작용)에서는 설문조사(survey)를 많이 사용한다.
피실험자에게 해당 시스템을 어떻게 느끼는 지 등의 기본적인 자료를 수집하는데 있어서 가장 쉬운 방법 중 하나이기 때문이다.
오늘은 연구 방법론으로써의 설문 조사를 체계적으로 이해하고 설계하는 법에 대해 다뤄보려고 한다.
서론: 왜 설문조사는 여전히 중요한가?
설문조사(Survey)는 사회과학과 공학 전반에서 가장 널리 사용되는 연구 방법 중 하나이다.
우리가 어떤 집단의 의견, 태도, 인식, 행동 패턴을 이해하고자 할 때 가장 먼저 떠올리는 방법이기도 하다.
HCI(Human–Computer Interaction) 연구에서도 설문은 사용자 경험, 기술 수용성, 인식 변화 등을 폭넓게 탐색하기 위한 기본 도구로 사용된다.
Survey는 well-defined and well-written set of questions to which an individual is asked to answer로 정의할 수 있다.
설문조사는 인구를 설명하거나 행동을 해석하고, 아직 충분히 탐색되지 않은 영역을 조사하는 데 효과적이다.
그러나 동시에 가장 비판받는 방법론 중 하나이기도 하다. 그 이유는 “쉬워 보이지만, 잘못 설계되면 신뢰하기 어려운 데이터를 낳기 때문”이다.
잘 설계된 설문은 방대한 집단으로부터 통계적으로 의미 있는 데이터를 수집할 수 있는 강력한 도구지만, 형식적이거나 검증되지 않은 설문은 오히려 연구의 신뢰성을 해친다.
따라서 설문은 단순한 질문지(questionnaire)가 아니라, 명확한 연구 목적·표집 설계·응답자 기준·분석 계획이 통합된 하나의 과학적 접근으로 다뤄져야 한다.
그래서 무엇보다 설문조사를 "잘 설계하는 것"이 중요하다.
설문은 대부분 자기기입식(self-administered) 형태로 진행된다.
즉, 연구자의 개입 없이 응답자가 스스로 작성한다.
이런 특성 때문에 인터뷰나 참여관찰과 같은 질적 연구에 비해 데이터의 깊이는 얕지만, 대신 넓은 범위의 표본을 빠르게 확보할 수 있다.
요약하자면, 설문조사는 “가장 적합하기 때문이 아니라, 가장 쉽기 때문에 선택되는 경우가 많다.” 하지만 HCI 연구에서는 단순히 ‘쉬운 방법’이 아니라, 잘 통제되고 체계적으로 설계된 설문이 사용자 경험을 정량적으로 이해하는 데 매우 유용하다.
설문조사의 장점과 한계
설문조사의 큰 장점 중 하나는 비용 대비 효율이 높다는 것이다.
온라인 도구(SurveyMonkey, Google Forms, Qualtrics 등)를 활용하면 짧은 시간 안에 수백 명 이상으로부터 데이터를 수집할 수 있다.
또한 지리적으로 분산된 사용자들로부터 동시에 응답을 받을 수 있어, 광범위한 인구 집단의 스냅샷(snapshot) 을 빠르게 얻을 수 있다.
설문은 또한 IRB(인간대상연구윤리위원회) 승인 절차에서도 비교적 non-intrusive으로 간주되며, 개인 인터뷰보다 부담이 적다.
이러한 이유로, HCI 연구에서 사용자 인식·태도·의도·만족도·특성 비교를 다루는 경우 설문은 가장 적절한 방법 중 하나다.
하지만 설문에는 명확한 한계가 있다.
첫째, 응답자가 기억에 의존하는 문항(예: ‘지난주에 이 앱을 몇 번 사용했습니까?’)은 회상 오류(recall bias)가 발생할 수 있다.
둘째, 흥미로운 패턴이 나타나더라도 즉각적인 후속 질문(follow-up) 이 불가능하다.
셋째, 문항이 불명확하거나 편향되어 있다면, 응답자는 의도와 다르게 답할 수 있고 결과의 타당성이 급격히 떨어진다.
따라서 설문조사는 깊은 정성적 이해를 제공하지는 못하지만, 정확한 표집 설계와 문항 구성만으로도 전체 사용자 집단의 경향을 예측할 수 있는 도구가 된다.
HCI 연구에서는 종종 실험이나 인터뷰 등 다른 방법과 결합해 “보완적 수단” 으로 사용된다.
연구 대상과 설문 목표 설정
설문조사는 많은 사람들로부터 데이터를 수집할 수 있기 때문에, 연구자는 우선 “누구로부터 응답을 받을 것인가?”를 명확히 해야 한다.
이를 위해 대상 집단(Target Population), 대상 응답자(Targeted Respondents), 그리고 포함 기준(Inclusion Criteria) 이라는 세 가지 개념이 중요하다.
- 대상 집단: 연구자가 관심을 갖는 전체 인구.
예: “모바일 헬스 앱을 사용하는 20–40대 직장인” - 대상 응답자: 실제로 설문을 받은 사람들.
- 포함 기준: 설문에 참여할 자격 조건.
예: “지난 한 달 내 앱 사용 경험이 있는 사람”
또한 설문을 배포할 때 필요한 모집단 프레임(population frame)—즉, 이메일 목록이나 사용자 데이터베이스—를 확보해야 한다.
HCI 연구에서는 이러한 명단이 불명확한 경우가 많기 때문에, 연구자는 종종 SNS, 커뮤니티, 혹은 컨퍼런스 네트워크 등을 활용한다.
만약 모집단이 명확히 정의되지 않았다면, 가능한 한 응답자 내 다양한 하위 집단(subgroup) 이 포함되도록 해야 한다.
예를 들어, “남녀, 연령대, 기술 숙련도”가 균형을 이루도록 표집을 설계하는 식이다..
확률 표집 Probabilistic Sampling
사회학에서 설문조사의 고전적인 목적은 전체 인구의 특성을 추정하는 것이다.
이를 가장 정확하게 달성하는 방법은 인구조사(census)이지만, 현실적으로는 불가능에 가깝다.
그래서 등장한 것이 확률 표집(probabilistic sampling) 이다.
확률 표집이란 모집단의 모든 구성원이 0보다 큰 확률로, 그리고 알려진 확률로 선택될 수 있는 표집 방식을 말한다.
즉, 각 참여자가 선택될 가능성이 명확히 정의되어 있고, 표본은 무작위로 선정된다.
예를 들어, 10,000명 중 500명을 무작위로 추출한다면, 이 500명은 전체 인구의 특성을 통계적으로 대변할 수 있다.
이 과정에서 포함 기준(inclusion criteria) 을 충족하고, 제외 기준(exclusion criteria) 을 위반하지 않아야 한다.
확률 표집은 “비용은 들지만, 일반화 가능성(generalizability)이 높은 방식”이다.
HCI 연구에서 IBM Beehive 연구(Chen et al., 2009)는 좋은 사례로, 전체 사용자 중 500명을 무작위로 선택해 230명의 유효 응답을 얻었다.
확률 표집은 또한 층화(Stratification) 기법을 사용해 대표성을 강화할 수 있다.
예를 들어, 미국 우체국의 주소 변경 데이터베이스에서 최근 이사한 6,000명을 표본으로 삼고, 이 중
1/3은 50마일 이내의 단거리 이사, 2/3은 장거리 이사로 나누는 식이다.
이는 장거리 이동이 중심 주제였기 때문에 특정 그룹의 비율을 조정한 것이다.
응답 규모(Response Size)는 신뢰수준(confidence level)과 허용 오차(margin of error)에 따라 달라진다.
Sue & Ritter(2007)에 따르면, 95% 신뢰 수준에서 ±5% 오차를 허용하려면 약 384명의 응답이 필요하다.

확률 표집의 주요 오류 유형
- 표집 오류(Sampling Error): 응답 수가 너무 적거나 표본이 충분히 대표하지 못할 때 발생한다.
예: 1만 명에게 발송했지만 100명만 응답. - 포괄 오류(Coverage Error): 모집단의 일부가 조사 대상에서 제외될 때 발생.
예: 이메일 주소가 없는 사람은 조사 기회가 없음. - 측정 오류(Measurement Error): 문항이 불명확하거나 편향된 경우.
- 비응답 오류(Nonresponse Error): 실제 응답자와 모집단의 통계적 구성이 다를 때.
예: 성별 비율이 모집단과 다름.
이러한 오류를 최소화하기 위해, 연구자는 표집 설계 단계에서부터 오차 요인을 예측하고 통제 전략을 마련해야 한다.
비확률 표집 Non-Probabilistic Sampling
앞서 다룬 확률 표집(probabilistic sampling) 은, 모집단의 모든 구성원이 동일하고 알려진 확률로 선택된다는 점에서 통계적으로 가장 이상적인 방식이다.
하지만 현실의 HCI 연구에서는 이런 이상적인 상황이 거의 없다.
예를 들어 “AI 어시스턴트를 사용하는 대학생”이나 “스마트워치를 쓰는 고령층” 같은 모집단은 명확하게 정의되어 있지도 않고, 중앙 데이터베이스나 공식 명단이 있는 것도 아니다.
이럴 때 연구자는 ‘무작위 추출(random)’이 불가능하다는 사실을 인정하고, 대신 실제 참여 가능한 사람들로부터 의미 있는 데이터를 수집하는 방향을 선택한다.
이게 바로 비확률 표집(non-probabilistic sampling) 이다.
왜 HCI에서는 비확률 표집이 흔한가?
HCI(Human–Computer Interaction) 연구의 목적은 단순히 모집단 전체의 평균을 추정하는 것이 아니라, ‘사람이 기술을 어떻게 경험하고 사용하는가’를 이해하는 것이다.
즉, “대표성(representativeness)”보다는 “맥락(context)”과 “경험의 다양성” 이 더 중요하다.
이 때문에 HCI 연구에서는 표본의 통계적 무작위성보다 현실적 접근성(accessibility) 을 우선시한다.
연구자는 실제로 시스템을 사용하는 사용자들을 중심으로 데이터를 수집하며, 이 과정에서 표집의 엄격한 통계적 기준보다는 연구의 목적에 부합하는 실질적 타당성을 추구한다.
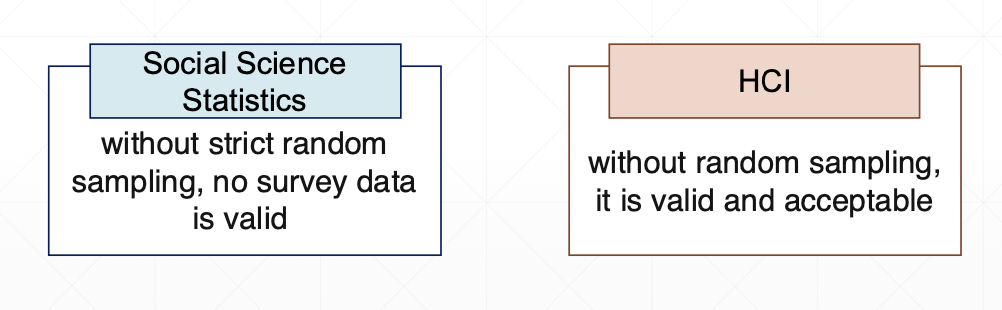
비확률 표집의 주요 형태
HCI 설문 연구에서 자주 사용되는 대표적인 비확률 표집 방법은 다음 3가지이다.
1. 자발적 참여 패널 (Volunteer Panels)
연구 참여를 자발적으로 신청한 사람들을 모아두고, 필요할 때마다 연구에 참여시키는 방식이다.
예를 들어 한 대학의 UX 연구실이 “디지털 헬스 앱 사용자 패널”을 운영한다면, 이 패널을 활용해 다양한 실험이나 설문을 진행할 수 있다.
- 장점: 연구 주제에 관심이 많고 성실히 응답하는 참여자 확보 가능
- 단점: 기술 친숙도나 관심 수준이 일반 사용자보다 높아 편향이 생길 수 있음
즉, ‘품질은 높지만 일반화는 어렵다’는 특성이 있다.
2. 자기 선택 설문 (Self-Selected Surveys)
사용자가 스스로 참여를 선택하는 방식이다.
예를 들어 웹사이트에 “AI 챗봇 사용 경험 설문에 참여해 주세요”라는 배너를 띄우거나, SNS에 설문 링크를 공개하는 경우가 여기에 해당한다.
이 방식은 참여 장벽이 낮고 빠르게 데이터를 모을 수 있다는 장점이 있다.
하지만 반대로 주제에 강한 관심을 가진 사람들만 참여하기 때문에 편향(bias)이 생길 수 있다.
예를 들어 챗봇에 불만이 있는 사람만 설문에 참여한다면 결과가 부정적으로 쏠릴 수 있다.
그럼에도 불구하고, 아직 연구되지 않은 주제나 새로운 사용자 현상을 탐색할 때는 가장 자연스럽고 효과적인 시작점이 된다.
조지아 공대(Georgia Tech)의 HCI 연구팀도 이 방식을 활용해 초기 사용자 행동 패턴을 관찰하는 연구를 여러 차례 수행했다.
3. 눈덩이 표집 (Snowball Sampling)
이미 확보한 응답자가 다른 참여자를 소개하는 방식이다.
처음 확보한 응답자가 친구나 동료에게 설문을 공유하면서 ‘눈덩이처럼’ 표본이 커지는 구조다.
이 방식은 접근하기 어려운 집단을 연구할 때 특히 효과적이다.
예를 들어 시각장애인의 보조기기 사용 경험을 조사하려는 경우, 처음 몇 명의 참여자가 본인이 속한 커뮤니티에서 다른 사람을 연결해줄 수 있다.
- 장점: 신뢰 관계가 형성된 집단에서 빠르게 확산
- 단점: 사회적 네트워크가 유사한 사람들끼리 연결되므로 다양성이 부족할 수 있음
비확률 표집의 신뢰성 높이기
비확률 표집에서는 "통계적 일반화"보다는 데이터의 타당성(validity) 확보가 중요하다.
연구자는 다음과 같은 방법으로 신뢰성을 높일 수 있다.
- 인구통계학적 정보 수집(Demographic Data)
연령, 성별, 직업, 교육 수준 등 기본 정보를 통해 응답 집단의 다양성을 평가할 수 있다. - 과표집(Oversampling)
모집단 규모를 정확히 모를 때는 가능한 한 많은 응답을 확보해야 한다.
응답 수가 많을수록 특정 집단이 완전히 배제될 가능성이 줄어들기 때문이다. - 사용 행위 기반 표집(Random Sampling of Usage)
사용자 대신 ‘사용 행위’를 단위로 표집. 예: “웹페이지가 10번째 로드될 때마다 팝업 설문 표시”. - 자기선택(Self-Selected) 설문
모든 방문자에게 설문 참여를 개방하는 방식. 예: 조지아 공대의 웹 설문(1994–1998)은 5,000명 이상의 응답을 확보했다.
설문 문항 개발
설문 문항 개발은 연구 설계 중 가장 섬세한 단계다.
응답자는 연구자의 도움 없이 스스로 설문을 읽고 작성해야 하므로, 모든 문항은 명확하고 중립적이며 이해하기 쉬워야 한다.
문항은 보통 세 가지 형식 중 하나로 구성된다.
- 개방형(Open-ended)
응답자가 자유롭게 의견을 기술.
→ 현상 이해에는 유용하지만, 분석이 어렵고 응답이 모호할 수 있다. - 폐쇄형(Closed-ended)
- 순서형(Ordered): Likert 척도(1~5, 1~9 등)를 사용.
예: “매우 만족 ~ 매우 불만족” - 비순서형(Unordered): 논리적 순서가 없는 범주형 선택지.
예: “성별”, “주 사용 디바이스”, “OS 종류”
- 순서형(Ordered): Likert 척도(1~5, 1~9 등)를 사용.
- 복합형(Hybrid)
폐쇄형 문항 끝에 “기타(Other): _______”을 추가해 부분적 개방성을 부여.
피해야 할 문항 유형
- 이중질문(Double-barreled): “이 앱은 빠르고 유용했습니까?” → “빠르다고 느끼셨습니까?” / “유용했습니까?”로 분리해야 한다.
- 부정표현(Negative wording): “불편하지 않다고 생각하지 않습니까?”
- 편향된 단어(Biased wording): “전문가들이 추천한 앱을 사용했습니까?”
- 감정적 단어(Hot-button words): “불쾌한 경험이 있었나요?”보다는 “불편했던 점이 있었나요?”가 적절하다.
기존의 검증된 설문 도구 활용
HCI 분야에는 이미 수십 년간 사용되어 온 검증된 설문 도구들이 존재한다.
새로운 설문을 무조건 처음부터 제작할 필요는 없다.
오히려 기존 도구를 일부 수정하거나 부분적으로 사용하는 것이 더 타당할 수 있다.
대표적인 도구들은 다음과 같다.
- CSUQ (Computer System Usability Questionnaire)
- ICTQ (Interface Consistency Testing Questionnaire)
- PUTQ (Perdue Usability Testing Questionnaire)
- QUIS (Questionnaire for User Interaction Satisfaction)
- SUMI (Software Usability Measurement Inventory)
- WAMMI (Website Analysis and MeasureMent Inventory)
이 설문들은 이미 타당도와 신뢰도가 검증되어 있어, 사용성 평가나 인터페이스 만족도 측정에 활용하기 좋다.
종이 설문과 온라인 설문
오늘날 대부분의 설문은 온라인으로 진행된다.
웹 기반 설문은 개발이 빠르고 비용이 거의 들지 않으며, 데이터가 자동으로 저장되어 분석 속도도 빠르다.
그러나 모든 연구에 온라인 방식이 적합한 것은 아니다.
인터넷 접근이 어려운 집단(예: 노년층, 저소득층, 특정 장애 집단)은 배제될 위험이 있다.
따라서 연구자는 연구 목적과 대상의 접근성을 고려해 종이 설문, 이메일 설문, 웹 설문 중 가장 적절한 방식을 선택해야 한다.
실제로는 접근성(accessibility) 이 결정 요인이다.
정기적인 오프라인 모임을 통해 대상자를 직접 만날 수 있다면 종이 설문이 적합하고, 이메일 주소 목록이 있다면 메일 설문을, 온라인 커뮤니티 기반이라면 웹 설문이 효율적이다.
또한 두 방식을 병행하는 혼합형 설문(Mixed-mode survey) 도 가능하다.
이 경우 응답자의 선택권이 넓어지고 표본의 다양성이 커질 수 있다.
단, 서로 다른 포맷(예: 종이 vs 웹)은 시각적 구조 차이로 편향(bias)을 유발할 수 있으므로 주의해야 한다.
온라인 설문은 익명성이 보장될 때 민감한 주제에서 더 솔직한 응답을 유도한다는 연구 결과도 있다(Sussman & Sproull, 1999).
특히 웹 기반 자기기입식 설문은 면접 방식보다 응답자의 심리적 방어를 줄인다(Couper, 2005).
다만, IRB 기준상 온라인 참여 동의서(informed consent) 를 명시적으로 제시해야 한다.
설문 배포 이후의 절차
설문은 배포로 끝나지 않는다.
오히려 진짜 품질은 “배포 전후의 절차 관리”에서 결정된다.
설문 데이터의 신뢰성과 타당성은 파일럿 테스트(pilot test), 응답률 관리(response rate), 그리고 데이터 분석(data analysis) 단계에서 좌우된다.
Pilot Testing
파일럿 테스트는 설문 문항과 구조의 적합성을 검증하기 위한 예비 실험이다.
설문을 본격적으로 배포하기 전에, 소규모 집단을 대상으로 미리 테스트를 수행하여 문항의 명확성, 흐름, 기술적 오류를 점검한다.
가장 널리 사용되는 접근은 Dillman(2000)의 3단계 사전검증(pretesting) 과정이다.
- 전문가 검토(Expert Review)
연구 주제와 관련 있는 동료나 전문가에게 설문 초안을 검토받는다.
논리적 일관성, 문항의 의미 모호성, 편향적 표현 등을 점검한다. - 사용자 피드백(User Feedback)
실제 응답자가 될 가능성이 있는 사람 2~3명을 대상으로 인터뷰를 진행한다.
설문을 작성하며 느낀 혼란, 흥미, 동기부여 수준 등을 탐색한다. - 파일럿 조사(Pilot Study)
최종 후보 설문을 소규모 집단(대략 5~10명)에게 실제 배포한다.
수집된 응답을 바탕으로 응답 누락, 중복 선택, 기타 응답 비율 등을 확인하고 설문 도구를 수정한다.
이 단계에서 발견되는 오류는 대부분 단순하지만 치명적이다.
예를 들어 “응답자가 특정 문항을 건너뛰었거나, 한 문항에 두 개의 답을 한 경우”, 혹은 “너무 많은 사람들이 ‘기타(Other)’를 선택한 경우” 등이 있다.
이런 문제는 설문 배포 전에 반드시 제거되어야 하는 구조적 결함이다.
파일럿 규모는 전체 연구 크기에 따라 다르다.
작은 연구(200–300 응답 예상)는 5–10명의 파일럿으로 충분하지만, 대규모 연구(수만 명 대상)는 더 많은 파일럿 응답자가 필요하다.
단, 파일럿 참여자는 최종 분석에는 포함되지 않아야 한다.
Response Rate 관리
잘 설계된 설문이라도 응답률이 낮으면 데이터 품질이 급격히 떨어진다.
응답률은 단순히 숫자가 아니라, 표본의 대표성과 신뢰도를 보증하는 지표다.
응답률을 높이는 주요 전략은 다음과 같다.
- 사전 안내문(Pre-contact letter)
설문 발송 전에 “누가 연구를 수행하는지, 왜 중요한지, 얼마나 시간이 걸리는지”를 명확히 안내한다.
신뢰성과 투명성을 확보하는 단계이다. - 응답 편의성 향상
종이 설문에는 **회신용 봉투(prepaid envelope)**를 동봉하고,
온라인 설문은 클릭 한 번으로 접근 가능한 짧은 URL과 모바일 친화형 화면을 제공한다. - 리마인더(Reminder)
응답하지 않은 사람에게 1~2회 리마인더 메일을 보내는 것이 일반적이다.
Dillman의 5단계 연락 모델(5-step process) 은 응답률 향상에 특히 효과적이다.- (1) 사전 안내문 발송
- (2) 설문 발송
- (3) 감사 및 리마인더 카드 발송
- (4) 2~4주 후 설문 재발송
- (5) 마지막으로 다른 채널(전화·이메일 등)로 접촉
- 인센티브 제공
설문 참여에 대한 보상은 소규모라도 효과적이다. 예: 추첨 쿠폰, 소정의 기념품, 연구 참여 증명서.
응답률이 20% 미만이라면, 표본 대표성에 심각한 문제가 있을 수 있다.
하지만 응답률이 40–60% 수준이면, 비확률 표본에서도 일정 수준의 타당성을 확보할 수 있다.
데이터 정제 및 분석
설문 데이터 분석은 크게 두 단계로 나뉜다.
- 정량 데이터 분석 (Quantitative Analysis)
- 기술통계(descriptive statistics): 빈도, 비율, 평균, 표준편차, 교차표(crosstabulation)
- 추론통계(inferential statistics): 상관관계, 회귀분석, 집단 간 차이검정 등
- 목적: 응답 패턴을 요약하고 가설을 통계적으로 검증한다.
- 정성 데이터 분석 (Qualitative Analysis)
- 개방형 문항(open-ended responses)은 코딩(coding) 작업을 거쳐 주제(theme)로 묶는다.
- 자연어 분석이나 키워드 빈도 분석을 통해 응답자 서술의 맥락을 이해한다.
이전에 수행해야 할 전처리 단계는 다음과 같다.
- 중복 응답 제거(duplicate filtering)
- 불완전 응답 제외(incomplete responses)
- 포함 기준(inclusion criteria) 미충족 응답자 제외
- 비정상 응답(패턴 반복, 극단치) 필터링
이 과정을 거쳐야만 통계적 신뢰성과 질적 타당성이 확보된다.
마무리 하며...
설문조사는 단순히 “많은 사람에게 물어보는 것”이 아니다.
HCI에서 설문은 사용자와 기술의 관계를 정량적으로 모델링하는 연구 방법이며, 잘 설계된 설문은 실험이나 로그 분석에서 포착하지 못하는 사람의 인식과 태도의 변화를 보여준다.
요약하자면, 설문은 다음과 같은 조건이 충족될 때 비로소 과학적 방법이 된다.
- 명확한 연구 목적과 변수 정의
– “무엇을 묻는가?”가 아니라 “왜 이걸 묻는가?”를 우선 정의한다. - 표집의 정당성 확보
– 모집단이 명확하지 않더라도 포함 기준과 응답자 특성을 투명하게 명시한다. - 문항의 타당성
– 이중질문, 부정문, 편향어, 감정어를 피한다. - 파일럿 검증 및 응답률 관리
– 설문을 발송하기 전에 반드시 시험하고, 응답 유도 전략을 세운다. - 적절한 분석 기법의 선택
– 단순한 빈도 분석을 넘어, 변수 간 관계를 추론하고 통찰을 도출한다.
HCI 연구자는 설문조사를 다른 연구 방법과 보완적(complementary) 으로 결합할 때 더 큰 효과를 얻을 수 있다.
예를 들어 로그 데이터나 사용자 실험 결과를 설문 응답과 결합하면, “행동(behavior)”과 “인식(perception)”의 간극을 분석할 수 있다.
결국 설문은 HCI 연구에서 사용자의 목소리를 데이터로 번역하는 첫 번째 도구다.
그리고 이 도구의 힘은, 얼마나 많은 응답을 모았는가가 아니라, 얼마나 정교하게 설계했는가에 달려 있다.